septiembre, 2009
-
Índices filtrados en SQL Server 2008
lunes, 21 de septiembre de 2009 a las 03:39hs por Dario Krapp
La intención de este artículo es la de comentar una de las nuevas capacidades de SQL Server 2008 que es la posibilidad de crear índices filtrados, pero me parece que es una buena oportunidad para mencionar que son los índices, cual es su objetivo, que tipos de índices existen y dejar para final del artículo este asunto de los índices filtrados.
Categoria SQL Server | Etiquetas: SQL Server 2008
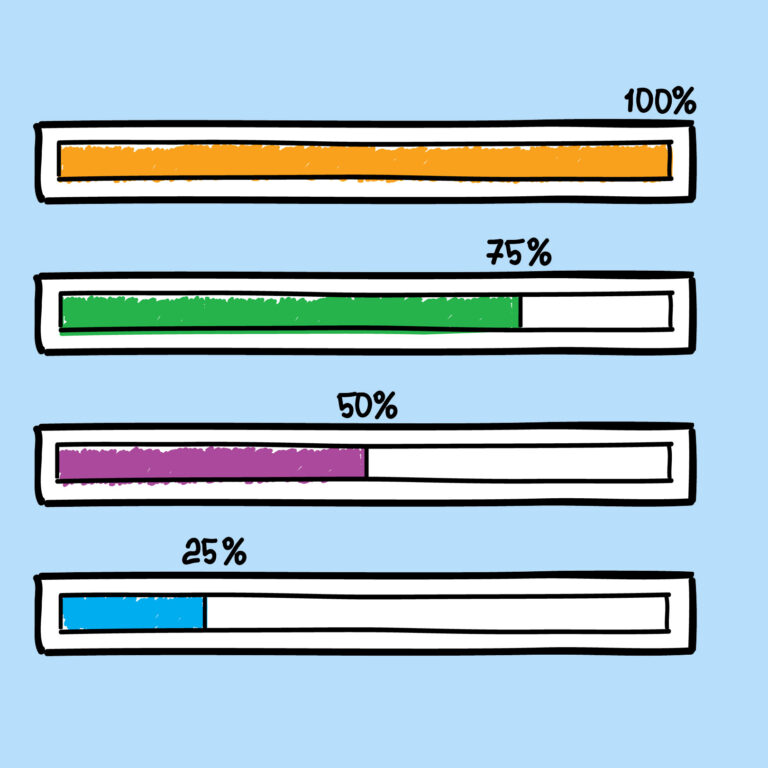
Barra de progreso en el ícono de la aplicación en la barra de tareas de Windows® 7
martes, 15 de septiembre de 2009 a las 23:46hs por Gustavo Cantero (The Wolf)
Cómo agregar una barra de progreso en el ícono de tu aplicación en la barra de tareas.
Categoria Windows Forms, WPF | Etiquetas:

Hipervínculo en WPF
lunes, 14 de septiembre de 2009 a las 23:37hs por Gustavo Cantero (The Wolf)
Cómo darle algún diseño o detalle parecido al de las páginas web a un hipervínculo de una aplicación de escritorio.
Categoria WPF | Etiquetas: WPF

Importación de archivos CSV con el comando Bulk Insert
lunes, 07 de septiembre de 2009 a las 16:42hs por Dario Krapp
En este artículo presentamos el comando BULK INSERT, el cual permite importar datos en formato CSV a una tabla en nuestro servidor SQL Server.
Categoria SQL Server | Etiquetas: BULK INSERT

")

