Categoría ‘Base de datos’
-

Evitar límite de tamaño de los campos de texto en el Management Studio
martes, 18 de junio de 2019 a las 22:57hs por Gustavo Cantero (The Wolf)
Cuando utilizamos el Microsoft SQL Server Management Studio para ejecutar consultas, puede ser que necesitemos obtener el valor de un campo que tenga muchas información de texto, pero esta herramienta tiene un límite en la longitud de los campos de texto cuando se visualiza en los resultados.
En este artículo explicamos un par de formas de evitar eso.Categoria SQL Server | Etiquetas: SQL Server
Enmascaramiento dinámico de datos en SQL Server 2016
miércoles, 05 de octubre de 2016 a las 11:44hs por Dario Krapp
En este artículo vamos a comentar de que se trata el enmascaramiento dinámico de datos que trae SQL Server 2016, arrancaremos desde cero y gradualmente con la ayuda de ejemplos cubriremos las posibilidades que esta nueva característica ofrece
Categoria SQL Server | Etiquetas: DDM, Dynamic Data Masking, Enmascaramiento de datos dinámicos, SQL Server 2016

Extraer parámetros de un Connection String de SQL Server desde C# en una línea
lunes, 02 de noviembre de 2015 a las 18:15hs por Dario Krapp
Una forma sencilla de tomar los parámetros de una cadena de conexión de SQL Server desde C#, en una línea de código y utilizando solamente funcionalidades del .NET Framework 2.0 o superior
Categoria .NET, SQL Server | Etiquetas: connection string, extraer parámetros

Hacer backup de todas las bases de un servidor MySQL o MariaDB en Linux
viernes, 30 de octubre de 2015 a las 16:57hs por Gustavo Cantero (The Wolf)
Uno de los problemas que podemos tener en un motor de base de datos utilizado para desarrollo es la constante creación y eliminación de bases, principalmente cuando tenemos muchos proyectos, lo que nos dificulta la tarea de hacer backups programados. Para automatizar esta tarea, en Scientia hicimos un script para Linux que busca las bases de datos de una instancia de MariaDB (o MySql), hace un backup de cada una y luego las comprime y las sube por FTP a nuestro servidor de backups utilizando como nombre del archivo la fecha actual.
Categoria Linux, MariaDB, MySQL | Etiquetas: backup, FTP, Linux, MariaDB

Actualizar las estadísticas de todas las bases de datos SQL Server
jueves, 09 de julio de 2015 a las 21:27hs por Gustavo Cantero (The Wolf)
En nuestros proyectos algunas veces tuvimos que forzar la actualización de las estadísticas para mejorar los tiempos de ejecución en las consultas de nuestras aplicaciones, principalmente en tablas que tienen muchas modificaciones de datos. Para esto tenemos comandos y procedimientos almacenados, pero si lo que queremos hacer es, por ejemplo, una tarea programada que actualice todas las tablas de todas las bases de datos de nuestro servidor de SQL Server, no tenemos nada que nos ayude. Por este motivo creamos este script que realiza esta tarea.
Categoria SQL Server | Etiquetas: estadisticas, sp_updatestats, statistics

Hacer backup de todas las bases de un servidor MySQL o MariaDB en Windows
domingo, 25 de mayo de 2014 a las 12:25hs por Gustavo Cantero (The Wolf)
Uno de los problemas que podemos tener en un motor de base de datos utilizado para desarrollo es la constante creación y eliminación de bases. Para automatizar esta tarea, en Scientia hicimos un script de linea de comando que revisa los archivos de la carpeta que contiene las bases de datos de nuestro MySQL, hace un backup de cada una y luego las comprime en una carpeta de la red (en nuestro caso dentro de un NAS) utilizando como nombre del archivo la fecha actual.
Categoria MariaDB, MySQL | Etiquetas: backup, rar

Hacer backup de todas las bases de un SQL Server
martes, 08 de abril de 2014 a las 12:48hs por Gustavo Cantero (The Wolf)
Uno de los problemas que podemos tener en un motor de base de datos utilizado para desarrollo es la constante creación y eliminación de bases, principalmente cuando tenemos muchos proyectos, lo que nos dificulta la tarea de hacer backups programados. Para resolver esto en Scientia hicimos un script que toma del diccionario de datos el nombre de cada base y hace un backup de las mismas guardándolos en una carpeta de la red (en nuestro caso dentro de un NAS), dentro de una carpeta creada con la fecha actual.
Categoria SQL Server | Etiquetas: backup, SQL Server

Reindexar todas las tablas de una base de SQL Server
jueves, 13 de marzo de 2014 a las 21:48hs por Gustavo Cantero (The Wolf)
Muchas veces nos a pasado que necesitamos reindexar todas las tablas de una base de datos del SQL Server y no encontramos un comando que lo haga. ¿A Uds. les pasó?
Bueno, para no entrar en pánico, especialmente si la base de datos tiene muchas tablas, armamos un script que obtiene sus nombres del diccionario de datos y ejecuta el comando DBCC REINDEX de SQL Server por cada una de ellas.Categoria SQL Server | Etiquetas: SQL Server
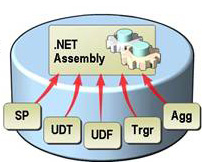
SQL CLR sobre SQL Server 2008 y Visual Studio 2010
lunes, 17 de diciembre de 2012 a las 21:34hs por Dario Krapp
En este artículo vamos a ver una introducción de lo que se conoce como SQL CLR que es básicamente, la posibilidad que ofrece SQL Server de ejecutar código .NET, en este caso vamos a utilizar SQL Server 2008 Express y C# con Visual Studio 2010 y vamos a crear un stored procedure, una table-valued function y un trigger utilizando esta tecnología.
Categoria .NET, SQL Server | Etiquetas: clr enabled, CREATE ASSEMBLY, SQL CLR, SQL CLR Database Project

Paginado desde SQL Server 2005 hasta 2012
miércoles, 12 de diciembre de 2012 a las 10:29hs por Dario Krapp
Es claro que una parte de las consultas que se realizan sobre un soporte de datos estarán destinadas a la obtención de listados y reportes, que permitan consultar los conjuntos de datos existentes, los reportes y el paginado estan muchas veces estrechamente unidos.
En este artículo veremos las posibilidades de paginado que ofrece SQL Server 2005 y 2008 a través de la función ROW_NUMBER y tablas derivadas. También veremos que posibilidades ofrece SQL Server 2012.Categoria SQL Server | Etiquetas: OFFSET, ROW_NUMBER

Cursores en SQL Server
jueves, 26 de noviembre de 2009 a las 10:27hs por Dario Krapp
En SQL Server un cursor puede definirse como un elemento que representará a un conjunto de datos determinado por una consulta T-SQL, el cursor permitirá recorrer fila a fila, leer y eventualmente modificar dicho conjunto de resultados. En este articulo daremos un paseo por las posibilidades de creación y uso de cursores disponibles.
Categoria SQL Server | Etiquetas: Cursor, SQL Server
Índices filtrados en SQL Server 2008
lunes, 21 de septiembre de 2009 a las 03:39hs por Dario Krapp
La intención de este artículo es la de comentar una de las nuevas capacidades de SQL Server 2008 que es la posibilidad de crear índices filtrados, pero me parece que es una buena oportunidad para mencionar que son los índices, cual es su objetivo, que tipos de índices existen y dejar para final del artículo este asunto de los índices filtrados.
Categoria SQL Server | Etiquetas: SQL Server 2008

Importación de archivos CSV con el comando Bulk Insert
lunes, 07 de septiembre de 2009 a las 16:42hs por Dario Krapp
En este artículo presentamos el comando BULK INSERT, el cual permite importar datos en formato CSV a una tabla en nuestro servidor SQL Server.
Categoria SQL Server | Etiquetas: BULK INSERT

Transacciones y modos de aislamiento en SQL Server y .NET
viernes, 03 de abril de 2009 a las 12:20hs por Dario Krapp
Comencemos por definir que es una transacción dentro del contexto de SQL Server, una transacción es un conjunto de operaciones …
continuar leyendoCategoria .NET, SQL Server | Etiquetas: .NET, SQL Server

Paginación en PHP orientada a objetos
lunes, 20 de octubre de 2008 a las 13:15hs por Dario Krapp
En este artículo repasamos los principales métodos en la paginación en PHP orientada a objetos
Categoria MySQL, PHP | Etiquetas: Objetos, OOP, Paginador, PHP
")


