Posts Tageados ‘.NET’
-

.NET 11 Preview 4 ya está disponible
miércoles, 20 de mayo de 2026 a las 14:20hs por Gustavo Cantero (The Wolf)
.NET 11 Preview 4 ya está disponible y llega con mejoras interesantes para desarrolladores: nuevas APIs para trabajar con procesos, optimizaciones en runtime y JIT, novedades en ASP.NET Core, avances en EF Core para búsqueda vectorial y mejoras de productividad en el SDK. Una preview para empezar a mirar lo que viene en la próxima versión de .NET.
Categoria .NET | Etiquetas: .NET, .net 11

101 ejemplos de Visual C# 2010 y Visual Basic 2010
miércoles, 14 de abril de 2010 a las 16:04hs por Gustavo Cantero (The Wolf)
Microsoft ha publicado dos paquetes gratuitos sobre C# 4.0 y Visual Basic 10.0, cada uno con documentación y 101 ejemplos para Visual Studio 2010 RTM.
Categoria .NET Framework, Visual Studio | Etiquetas: .NET, C#, Visual Basic, Visual Studio 2010

Betas de exámenes de certificación de .NET 4.0
miércoles, 17 de marzo de 2010 a las 18:17hs por Gustavo Cantero (The Wolf)

El día de hoy Microsoft ha lanzado una invitación a los desarrolladores a dar GRATUITAMENTE los exámenes de certificación para .NET Framework 4.0 en su modalidad beta. Quienes aprueben alguno obtendrán la certificación de la misma manera que si fueran los exámenes finales.Hoy agregaron más lugares!
Categoria .NET, Certificaciones | Etiquetas: .NET

Introducción a la programación con XNA 3.1 y C#
jueves, 04 de marzo de 2010 a las 14:16hs por Gustavo Cantero (The Wolf)
En el libro gratuito «A Simple Introduction to Game Programming With C# and XNA 3.1» se explica como desarrollar videojuegos a aquellos que no tienen ningún conocimiento de programación, enfocado en los conceptos y fundamentos de XNA.
Categoria XNA | Etiquetas: .NET, C#, XNA

Traductor gratuito de recursos de .NET
jueves, 14 de enero de 2010 a las 02:25hs por Gustavo Cantero (The Wolf)
En Scientia Soluciones Informáticas desarrollamos una aplicación sencilla pero muy útil utilizando los servicios de traducción que ofrece Bing: creamos un traductor de recursos de .NET, el cual se puede descargar, utilizar y distribuir de forma gratuita.
Categoria .NET Framework | Etiquetas: .NET, Globalizacion, Localizacion, Recursos

Transacciones y modos de aislamiento en SQL Server y .NET
viernes, 03 de abril de 2009 a las 12:20hs por Dario Krapp
Comencemos por definir que es una transacción dentro del contexto de SQL Server, una transacción es un conjunto de operaciones …
continuar leyendoCategoria .NET, SQL Server | Etiquetas: .NET, SQL Server

Conversiones de colores en .NET
jueves, 13 de noviembre de 2008 a las 18:22hs por Gustavo Cantero (The Wolf)
Cómo convertir colores a distintos formatos desde .NET: HTML, Win32 y Ole.
Categoria .NET | Etiquetas: .NET, Color, ColorTranslator, HTML, Ole, Win32

Ya salió la versión RTM de Silverlight 2.0
viernes, 17 de octubre de 2008 a las 13:16hs por Gustavo Cantero (The Wolf)
El 13 de Octubre Microsoft anunció, a través de un comunicado de prensa, la versión RTM de Silverlight 2.0, la cual está disponible para descargarse desde el 14 de octubre desde la página de Silverlight.
Categoria Silverlight | Etiquetas: .NET, Blend, eclipse4sl, Expression, Silverlight, Visual Web Developer 2008

Eliminar archivos temporales de ASP.NET
jueves, 18 de septiembre de 2008 a las 12:10hs por Gustavo Cantero (The Wolf)
En este artículo veremos cómo eliminar archivos temporales de ASP.NET para asegurarnos de que la aplicación se esté actualizando correctamente
Categoria .NET, ASP.NET, IIS | Etiquetas: .NET, ASP.NET, Cache, IIS
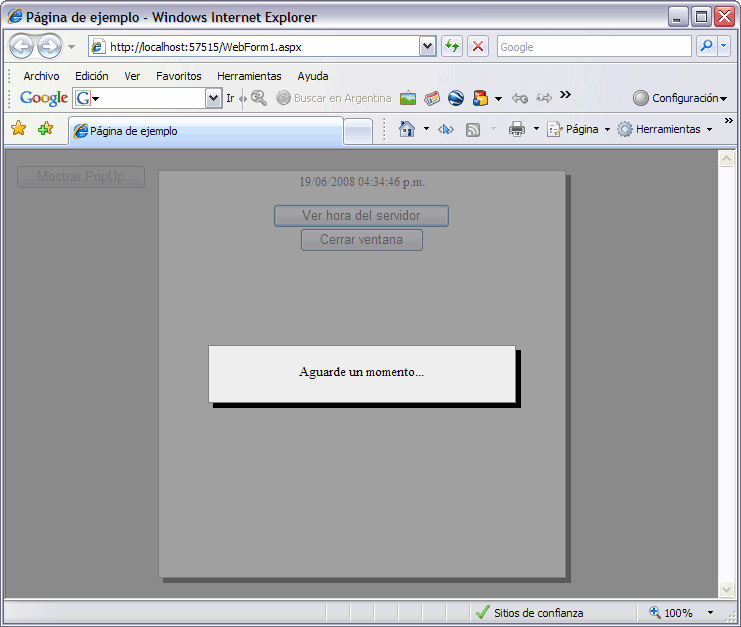
Deshabilitar controles de la página hasta que finalicen los UpdatePanels
jueves, 19 de junio de 2008 a las 00:30hs por Gustavo Cantero (The Wolf)
Método para deshabilitar los controles de una página mientras se ejecuta la actualización de algún UpdatePanel de la misma
Categoria AJAX, ASP.NET | Etiquetas: .NET, AJAX, AjaxControlToolkit, ASP.NET
Acerca de nosotros
miércoles, 11 de junio de 2008 a las 20:42hs por Gustavo Cantero (The Wolf)
Programando a medianoche es sin ninguna duda algo que a cualquier programador le debe resultar conocido, ya que…
Categoria General | Etiquetas: .NET, Dario Krapp, Gustavo Cantero, Quienes Somos, Scientia
")


